Neural Network Neuron(Perceptron)
Neuron(Perceptron) z j l = ∑ k ω j k l a k l − 1 + b j l z^l_j = \sum_k{\omega^l_{jk}a^{l-1}_k} + b^l_j z j l = k ∑ ω jk l a k l − 1 + b j l a j l = σ ( z j l ) a^l_j = \sigma\left(z^l_j\right) a j l = σ ( z j l ) Loss function
L2 loss function
L o s s ≡ 1 2 ∥ y − a L ∥ 2 = 1 2 ∑ i ( y i − a i L ) 2 Loss \equiv \frac{1}{2} \lVert \mathbf{y} - \mathbf{a}^L \rVert^2 = \frac{1}{2} \sum_i{\left(y_i - a^L_i\right)^2} L oss ≡ 2 1 ∥ y − a L ∥ 2 = 2 1 i ∑ ( y i − a i L ) 2 L o s s ≥ 0 ( y 는 주어진 답 ) Loss \geq 0 \quad \left(\mathbf{y}\text{ 는 주어진 답}\right) L oss ≥ 0 ( y 는 주어진 답 ) Neural Network Training
Neural Network Training을 통해 찾아야 할 것은 L o s s Loss L oss weights와 biases입니다. w \mathbf{w} w
L o s s n e x t = L o s s + Δ L o s s ≈ L o s s + ∇ L o s s ⋅ Δ w Loss_{next} = Loss + \Delta Loss \approx Loss + \nabla Loss \cdot \Delta \mathbf{w} L os s n e x t = L oss + Δ L oss ≈ L oss + ∇ L oss ⋅ Δ w L o s s Loss L oss ∇ L o s s ⋅ Δ w < 0 \nabla Loss \cdot \Delta \mathbf{w} < 0 ∇ L oss ⋅ Δ w < 0 Δ w \Delta \mathbf{w} Δ w
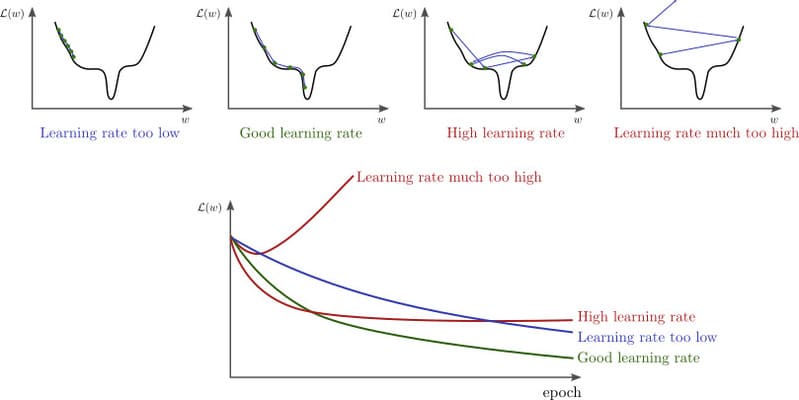
Δ w = − η ∇ L o s s = − ϵ ∇ L o s s ∥ ∇ L o s s ∥ ( ϵ > 0 ) \Delta \mathbf{w} = - \eta \nabla Loss = - \epsilon \frac{\nabla Loss}{\lVert \nabla Loss \rVert} \quad ( \epsilon > 0) Δ w = − η ∇ L oss = − ϵ ∥ ∇ L oss ∥ ∇ L oss ( ϵ > 0 ) η \eta η learning rate이고, ϵ \epsilon ϵ step입니다. 만약 step이 너무 크다면, L o s s Loss L oss
Δ w \Delta \mathbf{w} Δ w w n e x t \mathbf{w}_{next} w n e x t
w n e x t = w + Δ w \mathbf{w}_{next} = \mathbf{w} + \Delta \mathbf{w} w n e x t = w + Δ w Stochastic Gradient Descent(SGD)
∇ L o s s = 1 n ∑ x ∇ L o s s x \nabla Loss = \frac{1}{n}\sum_x{\nabla Loss_x} ∇ L oss = n 1 x ∑ ∇ L os s x 훈련을 위한 데이터셋이 큰 경우, 시간이 많이 걸릴 수 있습니다. 전체 데이터셋에서 랜덤으로 데이터를 선택해 만든 데이터셋 X 1 , X 2 , . . . , X m X_1, X_2, ..., X_m X 1 , X 2 , ... , X m
∇ L o s s = 1 n ∑ x ∇ L o s s x ≈ 1 m ∑ i = 1 m ∇ L o s s X i \nabla Loss = \frac{1}{n}\sum_x{\nabla Loss_x} \approx \frac{1}{m}\sum^m_{i=1}{\nabla Loss_{X_i}} ∇ L oss = n 1 x ∑ ∇ L os s x ≈ m 1 i = 1 ∑ m ∇ L os s X i
batch 크기가 줄어 한 step을 계산하는데 걸리는 시간이 줄어듭니다.
수렴하는 데 필요한 step 수가 증가합니다.
mini-batch의 크기가 작을 수록 batch의 분포가 전체 데이터 셋의 분포와 달라질 확률이 높기 때문에 학습이 불안정해집니다.
(계산 시간/step) * (수렴에 필요한 step)을 학습 시간이라고 하면, 학습 시간이 최소가 되는 batch 크기가 존재합니다.
Forward-propagation
Forward-propagation (or forward pass)는 입력부터 출력으로 이어지는 네트워크를 순서대로 계산하고 그 결과를 저장하는 과정을 말합니다.
Back-propagation
Back propagation z j l = ∑ k ω j k l a k l − 1 + b j l z^l_j = \sum_k{\omega^l_{jk}a^{l-1}_k} + b^l_j z j l = k ∑ ω jk l a k l − 1 + b j l a j l = σ ( z j l ) a^l_j = \sigma\left(z^l_j\right) a j l = σ ( z j l ) L o s s Loss L oss Back-propagation을 사용하여 ∇ L o s s \nabla Loss ∇ L oss
l l l j j j δ j l \delta^l_j δ j l
δ j l ≡ ∂ L o s s ∂ z j l \delta^l_j \equiv \frac{\partial Loss}{\partial z^l_j} δ j l ≡ ∂ z j l ∂ L oss z j l z^l_j z j l δ l + 1 \mathbf{\delta}^{l+1} δ l + 1 δ j l \delta^l_j δ j l
δ j l = ∂ L o s s ∂ z j l = ∑ i ∂ L o s s ∂ z i l + 1 ∂ z i l + 1 ∂ z j l ( ∂ z i l + 1 ∂ z j l = ω i j l + 1 σ ′ ( z j l ) ) = ∑ i ∂ L o s s ∂ z i l + 1 ω i j l + 1 σ ′ ( z j l ) = ∑ i δ i l + 1 ω i j l + 1 σ ′ ( z j l ) \begin{aligned}
\delta^l_j = \frac{\partial Loss}{\partial z^l_j}
& = \sum_i{\frac{\partial Loss}{\partial z^{l+1}_i} \frac{\partial z^{l+1}_i}{\partial z^l_j}}
\quad \left( \frac{\partial z^{l+1}_i}{\partial z^l_j} = \omega^{l+1}_{ij} \, \sigma' \left(z^l_j\right) \right)\\
& = \sum_i{\frac{\partial Loss}{\partial z^{l+1}_i} \omega^{l+1}_{ij} \, \sigma' \left(z^l_j\right)} \\
& = \sum_i{\delta^{l+1}_i \omega^{l+1}_{ij} \, \sigma' \left(z^l_j\right)}
\end{aligned} δ j l = ∂ z j l ∂ L oss = i ∑ ∂ z i l + 1 ∂ L oss ∂ z j l ∂ z i l + 1 ( ∂ z j l ∂ z i l + 1 = ω ij l + 1 σ ′ ( z j l ) ) = i ∑ ∂ z i l + 1 ∂ L oss ω ij l + 1 σ ′ ( z j l ) = i ∑ δ i l + 1 ω ij l + 1 σ ′ ( z j l ) L2 loss를 사용한다면, a j L a^L_j a j L δ j L = ( a j L − y j ) σ ′ ( z j L ) \delta^L_j = (a^L_j - y_j) \, \sigma' \left( z^L_j \right) δ j L = ( a j L − y j ) σ ′ ( z j L )
δ j L = ( a j L − y j ) σ ′ ( z j L ) \delta^L_j = (a^L_j - y_j) \, \sigma' \left( z^L_j \right) δ j L = ( a j L − y j ) σ ′ ( z j L ) δ j L − 1 = ∑ i δ i L ω i j L σ ′ ( z j L − 1 ) ⋮ \delta^{L-1}_j = \sum_i{ \delta^L_i \omega^L_{ij} \, \sigma' \left(z^{L-1}_j\right)} \\
\vdots δ j L − 1 = i ∑ δ i L ω ij L σ ′ ( z j L − 1 ) ⋮ 결과적으로 ∇ L o s s \nabla Loss ∇ L oss
∂ L o s s ∂ b j l = ∂ L o s s ∂ z j l ∂ z j l ∂ b j l = δ j l \frac{\partial Loss}{\partial b^l_j} = \frac{\partial Loss}{\partial z^l_j} \frac{\partial z^l_j}{\partial b^l_j} = \delta^l_j ∂ b j l ∂ L oss = ∂ z j l ∂ L oss ∂ b j l ∂ z j l = δ j l ∂ L o s s ∂ ω j k l = ∂ L o s s ∂ z j l ∂ z j l ∂ ω j k l = δ j l a k l − 1 \frac{\partial Loss}{\partial \omega^l_{jk}} = \frac{\partial Loss}{\partial z^l_j} \frac{\partial z^l_j}{\partial \omega^l_{jk}} = \delta^l_j a^{l-1}_k ∂ ω jk l ∂ L oss = ∂ z j l ∂ L oss ∂ ω jk l ∂ z j l = δ j l a k l − 1 Training
초기 weights and biases를 랜덤하게 설정하고, Forward-propagation -> Back-propagation -> weights and biases update를 반복하는 것을 Training이라고 합니다. L o s s Loss L oss
Initialization
입력의 분산보다 출력의 분산이 커지면 활성화 함수에 따라 수렴하는 부분이 생길 수 있고, 이것은 Vanishing gradient 문제를 야기할 수 있습니다.
변수를 적절히 초기화 해주는 것은 Vanishing gradient, Exploding gradient 등의 문제 해결에 도움이 되고, 훈련속도를 높일 수 있습니다.
Reference