Neural Network CPU vs. GPU vs. NPU
Google's product News
How a CPU works
... A CPU has to store the calculation results on memory inside CPU (so called registers or L1 cache) for every single calculation. This memory access becomes the downside of CPU architecture called the von Neumann bottleneck. ...
How a GPU works
... The modern GPU usually has 2,500–5,000 ALUs in a single processor that means you could execute thousands of multiplications and additions simultaneously. For every single calculation in the thousands of ALUs, GPU need to access registers or shared memory to read and store the intermediate calculation results. ...
How a TPU works
... The key enabler is a major reduction of the von Neumann bottleneck. So hardware designer place thousands of multipliers and adders and connect them to each other directly to form a large physical matrix of those operators. This is called systolic array architecture.
Let's see how a systolic array executes the neural network calculations. At first, TPU loads the parameters from memory into the matrix of multipliers and adders.
Then, the TPU loads data from memory. As each multiplication is executed, the result will be passed to next multipliers while taking summation at the same time. So the output will be the summation of all multiplication result between data and parameters. During the whole process of massive calculations and data passing, no memory access is required at all. ...
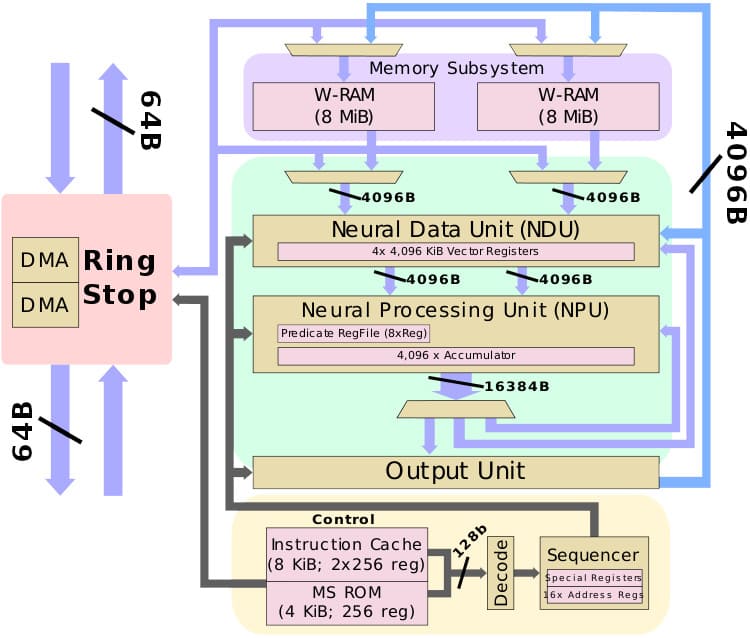
CHA Diagram
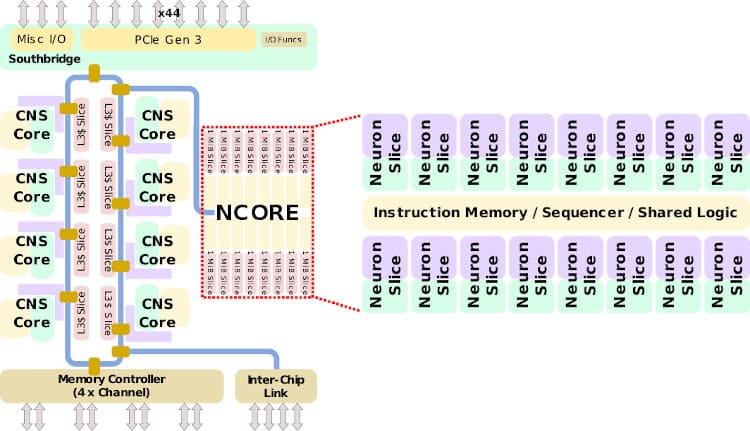
SoC
CNS-core
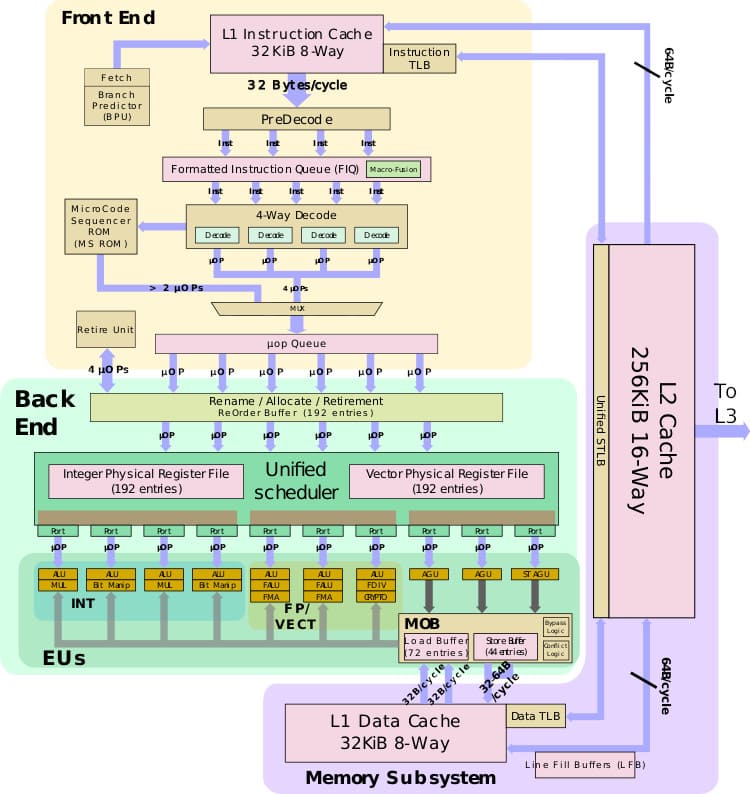
N-core