Ceph OSD 관리
Disk 준비
아래 중 하나에 해당하는 Disk를 준비해야합니다.
- Raw devices (파티션 또는 파일 시스템이 없는 디바이스)
- Raw partitions (파일 시스템이 없는 파티션)
- LVM Logical Volumes (파일 시스템이 없는 논리적 볼륨)
Block모드로 사용가능한 PV(다른 StorageClass에 의해 프로비저닝 됨)
Raw device를 사용하는 경우
sudo dd if=/dev/zero of=/dev/<device> bs=1M count=100 oflag=direct,dsync
Logical Volume(LV)를 사용하는 경우
Data 흐름
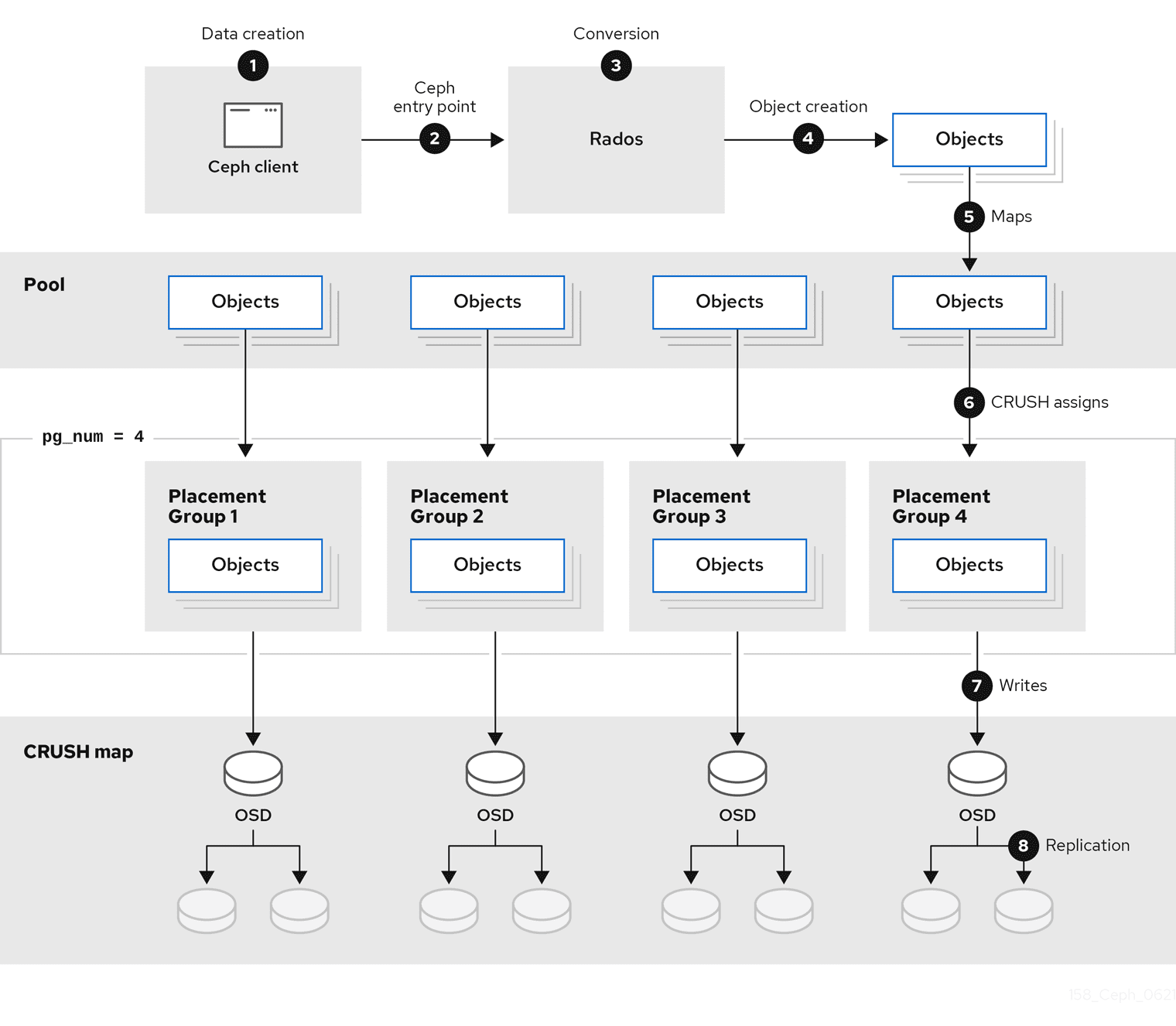
https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/4/html/storage_strategies_guide/overview
- Data
- block device image(RBD), object(RGW), file(CephFS)
- Data는 저장을 위한 Object로 분할되고(e.g., 4 MB), Object는 stripe unit으로 분할됩니다(e.g., 64 KB).
- Data Striping
- Pool
- 클라이언트가 인식하는 추상화된 저장공�간입니다.
- Pool은 Placement Group(PG)들로 나뉩니다.
- 하나의 PG는 하나의 Pool에만 속합니다.
- CRUSH 알고리즘
- PG를 OSD에 할당합니다.(primary OSD와 secondary OSDs로 구성)
- Object를 PG 중 하나에 할당합니다.
- CRUSH 맵
- Bucket 계층 구조, OSD 리스트, Pool 내에서 데이터를 복제 규칙을 정의한 맵입니다.
- OSD가 추가되면
hostBucket에 자동으로 추가됩니다. - 기본적으로
root-host-osd구조가 주어집니다. root-region-zone-datacenter-room-pod-pdu-row-rack-chassis-host-osd구조로 확장 가능합니다.
kubectl rook-ceph ceph osd tree
OSD 추가하기
apiVersion: ceph.rook.io/v1
kind: CephCluster
spec:
resources:
osd: {}
placement:
all: {}
osd: {}
storage:
useAllNodes: false
useAllDevices: false
동일한 설정이 있는 경우 범위가 좁은 것이 적용됩니다. 예를 들어 storage.config와 storage.nodes.config가 있고 해당 장치가 속한 Node에 config가 있는 경우 storage.nodes.config가 적용됩니다.
resourcesosd: {}osd-<deviceClass>: {}<deviceClass>에는hdd,ssd,nvme등이 올 수 있습니다.
- 메모리 설정은 자동으로
osd_memory_target설정에 적용됩니다.
placementallosdnodeAffinitypodAffinitypodAntiAffinitytolerationstopologySpreadConstraints
storageconfig: <config>- deviceSelection(임베딩)
storageClassDeviceSets: []onlyApplyOSDPlacement: <bool>- PV가 아닌 장치를 사용하는 경우
.spec.placement.osd와.spec.placement.all의 병합 여부입니다. - PV 장치를 사용하는 경우
storageClassDeviceSets에 정의된 placement와.spec.placement.all의 병합 여부입니다.
- PV가 아닌 장치를 사용하는 경우
useAllNodes: <bool>: 모든 노드에서 장치를 감지할지 여부입니다.nodes: []name: <nodeName>config: <config>- 노드에 있는 모든 장치에 적용될 설정입니다.
- deviceSelection(임베딩)
resources: {}- 메모리 설정은 자동으로
osd_memory_target설정에 적용됩니다.
- 메모리 설정은 자동으로
- deviceSelection
useAllDevices: <bool>deviceFilter: <deviceRegex>devicePathFilter: <devicePathRegex>devices: []name: <device|devicePath>config: <config>
volumeClaimTemplates: []
resources에 memory 설정을 하는 경우 osd_memory_target 설정에 반영됩니다. 스토리지만을 위한 Node의 경우 osd_memory_target_autotune와 autotune_memory_target_ratio을 활용하는 것이 좋습니다.
OSD 제거하기
kubectl rook-ceph ceph status
cluster.helath가 HEALTH_OK인지 확인합니다.data.pgs의 모든 pg가 active+clean인지 확인합니다.data.usage의 avail 용량이 OSD를 제거한 후 backfilling, rebalancing 등을 고려했을 때 충분한지 확인합니다.
상태확인이 끝난 후, CephCluster CR에 device를 직접 선언한 경우 제거하려는 devvice를 CR에서 제거합니다. 한 번에 너무 많은 device를 제거하면 안됩니다.
OSD를 제거하는 동안 operator가 제거된 device를 검색해서 다시 추가하려고 시도할 수 있는 경우, 이를 막기 위해 작업이 끝날 때까지 operator의 수를 0으로 설정하여 중지시켜야합니다.
failureDomain이 host인 경우 최대 같은 Node에 있는 OSD 전부, osd인 경우 OSD 하나만 제거한 후 모든 작업이 끝날 때까지 기��다렸다가 다음 작업을 진행해야합니다.
아래 명령어를 통해 OSD를 down 상태로 변경합니다.
kubectl -n rook-ceph scale deploy/rook-ceph-osd-<OSDID> --replicas=0
kubectl rook-ceph ceph osd df osd.<OSDID>
kubectl rook-ceph rook purge-osd <OSDID> --force
OSD가 제거된 후 클러스터 상태가 HEALTH_OK인지 확인합니다.
kubectl rook-ceph ceph status
backfilling 속도를 높이기 위해 아래와 같은 설정을 적용할 수 있습니다.
kubectl rook-ceph ceph config set osd osd_mclock_profile high_recovery_ops
kubectl rook-ceph ceph tell 'osd.*' injectargs '--osd-max-backfills 20'
kubectl rook-ceph ceph config show osd.<OSDID> osd_max_backfills
작업이 끝나면 초기 설정으로 되돌려야합니다.
kubectl rook-ceph ceph tell 'osd.*' injectargs '--osd-max-backfills 1'
kubectl rook-ceph ceph config set osd osd_mclock_profile balanced
Ceph OSD 설정
kubectl rook-ceph ceph osd set <option>
<option>pause- 읽기/쓰기 작업을 중지합니다.(in, out, up, down 상태에 영향을 주진 않습니다.)
noout- 클러스터에 OSD가 없다고 판단하는 상태를 out이라고 합니다.
- OSD가 MON에게 report하지 않으면 out으로 처리됩니다.
- OSD가 out으로 처리되는 것을 막습니다.
nodown- 클러스터에 OSD가 있지만 작동하지 않는 상태를 down이라고 합니다.
- 네트워크 이슈 등으로 인해 heartbeat 문제가 생기면 down으로 처리됩니다.
- OSD가 down으로 처리되는 것을 막습니다.
nobackfillnorebalancenorecovernoscrubnodeep-scrub