DeepSeek-V3
DeepSeek-V3 Transformer Block
DeepSeek-V3는 Masked Self Attention으로 Multi-Head Latent Attention을 사용하고, Feed-Forward Network으로 DeepSeekMoE를 사용하는 Transformer Block을 쌓은 Decoder-Only Transformer 구조의 LLM입니다.
Rotary Positional Embedding(RoPE)
Multi-Head Latent Attention(MLA)
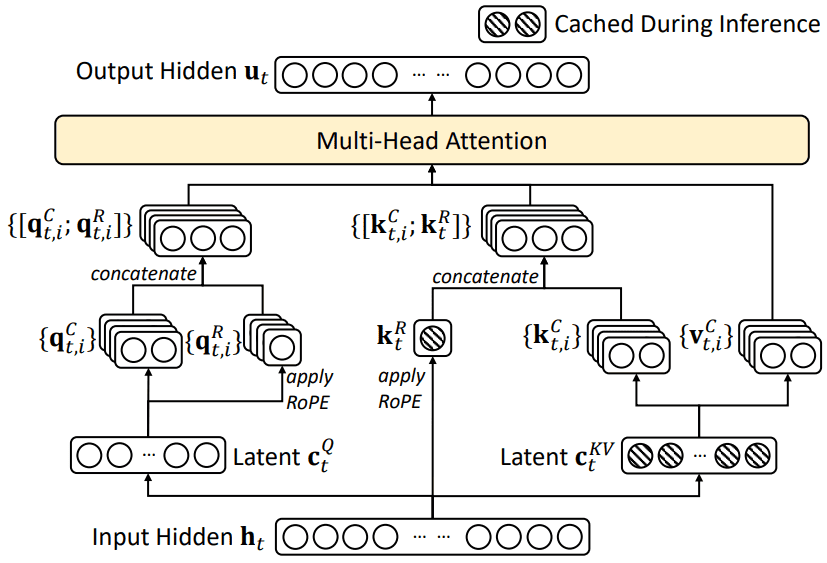
Figure 2. Multi-Head Latent Attention(MLA)
Latent를 도입하여 MHA를 사용할 때 보다 연산 효율, 메모리 사용량, KV cache 크기 등에서 향상된 성능을 보이는 Attention입니다.
- Latent
- CKV=XWDKV∈Rn×dc (dc≪dhnh)
- CQ=XWDQ∈Rn×dc′ (dc′≪dhnh)
- Query
- QiC=CQWiUQ∈Rn×dhnh
- QiR=RoPE(CQWiQR)∈Rn×dhRnh
- Qi=Concat(QiC,QiR)∈Rn×(dh+dhR)nh
- Key
- KiC=CKVWiUK∈Rn×dhnh
- KR=KiR=RoPE(CKVWKR)∈Rn×dhRnh
- Ki=Concat(KiC,KiR)∈Rn×(dh+dhR)nh
- Value
- ViC=CKVWiUV∈Rn×dhnh
Mixture of Experts(MoE)
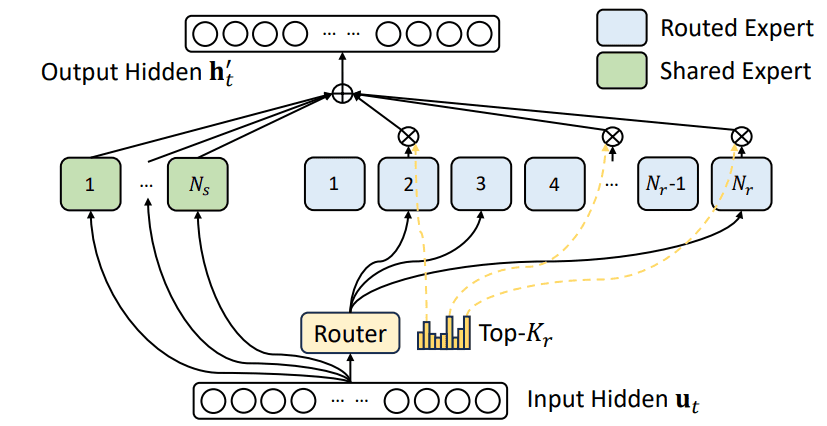
Figure 2. DeepSeekMoE
- sit=Sigmoid(xtTei)
- git′={sit0,sit∈Topk({sjt∣1⩽j⩽Nr},Kr), otherwise
- git=∑j=1Nrgjt′git′
- MoE(xt)=xt+∑i=1NsFFNis(xt)+∑i=1NrgitFFNir(xt)
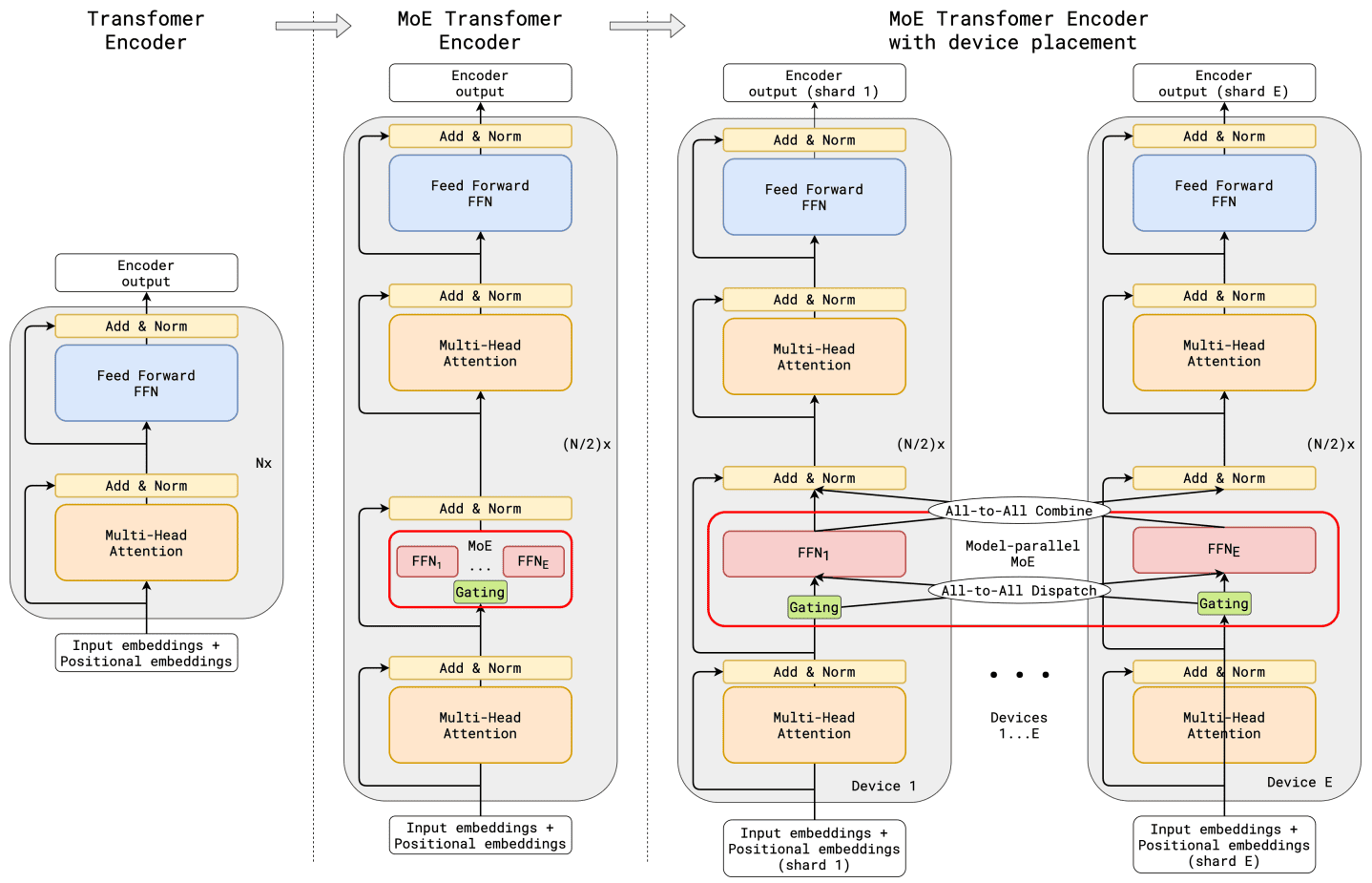
Figure 3. Illustration of scaling of Transformer Encoder with MoE Layers
(GShard)