Beyond the Buzz (2506) - A Pragmatic Take on Inference Disaggregation
Introduction
ISL >> OSL인 상황에서 10 B 이상 모델을 사용하는 경우 Prefill/Decode Disaggregation을 사용하면 큰 성능 향상을 기대할 수 있습니다.
Background
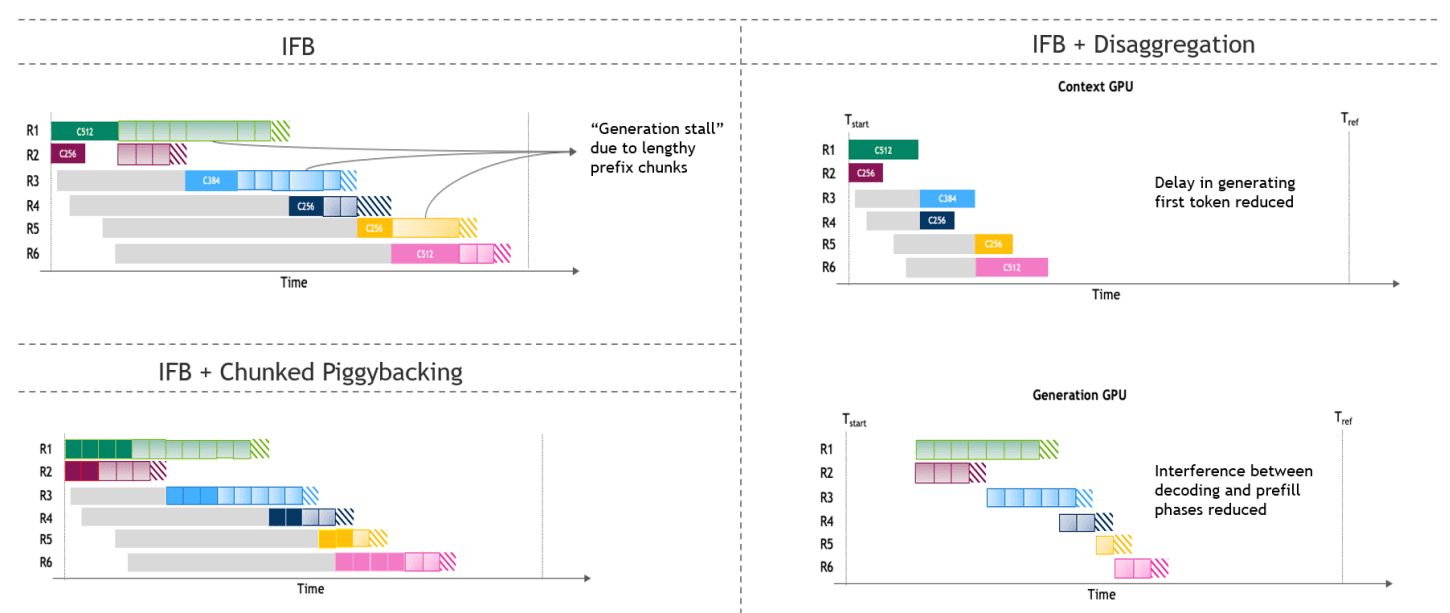
Figure 2: Visualization of (left) co-located and (right) disaggregated inference serving
- co-located serving 성능을 최대화하기 위해 In-flight batching(Continuous batching)과 Piggybacking(Chunked prefill)을 사용합니다.
- In-flight batching과 disaggregation을 사용하면 co-located 에서 발생하는 prefill 지연을 줄일 수 있습니다.
Design space exploration
Model partitioning
모델 성능 자체를 최적화하기 위해 아래와 같은 전략을 사용합니다.
- Tensor Parallelism (TP)
- Expert Parallelism (EP)
- Pipeline Parallelism (PP)
- Chunked Pipeline Parallelism (CPP)
- Tensor Parallel Attention and EP FFNs (TEP)
주어진 모델에 대한 최적화된 파티셔닝 전략은 아래와 같은 요소에 영향을 받습니다.
- model architecture
- co-located or dissaggregated
- traffic 특성(ISL, OSL, QPS, ...)
- target HW(GPU, NPU, ...)
- latency 제약 조건(TTFT, TPOT, E2EL)
Scaling and rate matching
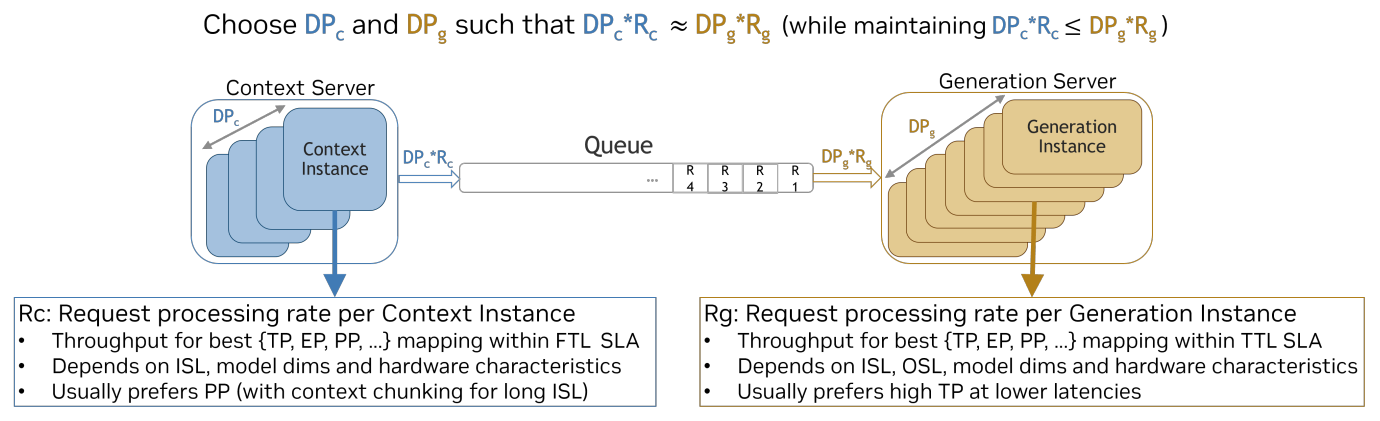
Figure 3: High-level overview of rate matching for disaggregated serving
적절한 prefill/decode 비율을 결정하고 두 단계 사이의 출력을 맞추기 위해 rate matching 전략을 사용합니다.
- FTL SLA를 만족하기 위한 prefill 설정들을 찾습니다.
- TTL SLA를 만족하기 위한 decode 설정들을 찾습니다.
- (prefill 수 * prefill 당 요청 처리 속도) (decode 수 * decode 당 요청 처리 속도) 를 만족하는 prefill/decode 수 조합을 찾습니다.
Disaggregation in practice
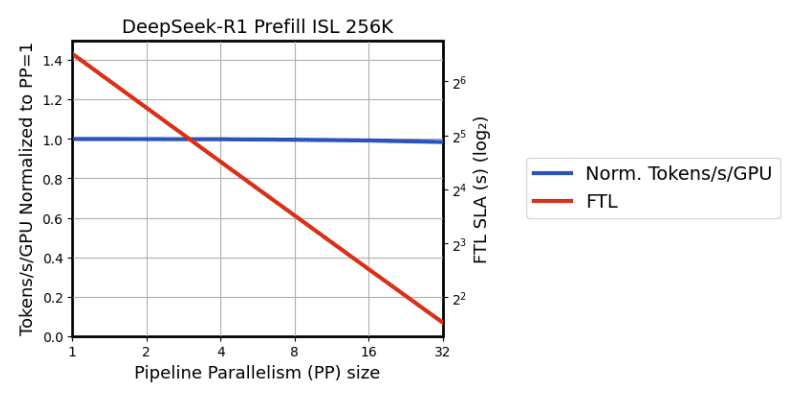
- 같은 수의 GPU를 사용할 때, prefill의 PP 크기를 키우면 throughput (tokens/s/GPU)은 유지하면서 FTL을 줄일 수 있습니다.
- batch size를 줄이고 TP 크기를 키우면 TTL을 줄일 수 있습니다. 1 / TTL는 interactivity (tokens/s/user)로 생각할 수 있습니다.
throughput (tokens/s/GPU) 과 interactivity (tokens/s/user) 사이에는 trade-off가 존재하며, 이를 Pareto frontier로 표현할 수 있습니다.
Model sensitivity
- Model architecture sensitivity
- Model size sensitivity
- 큰 모델일수록 dissaggregation에 의한 성능 향상 효과가 큽니다.
Traffic sensitivity
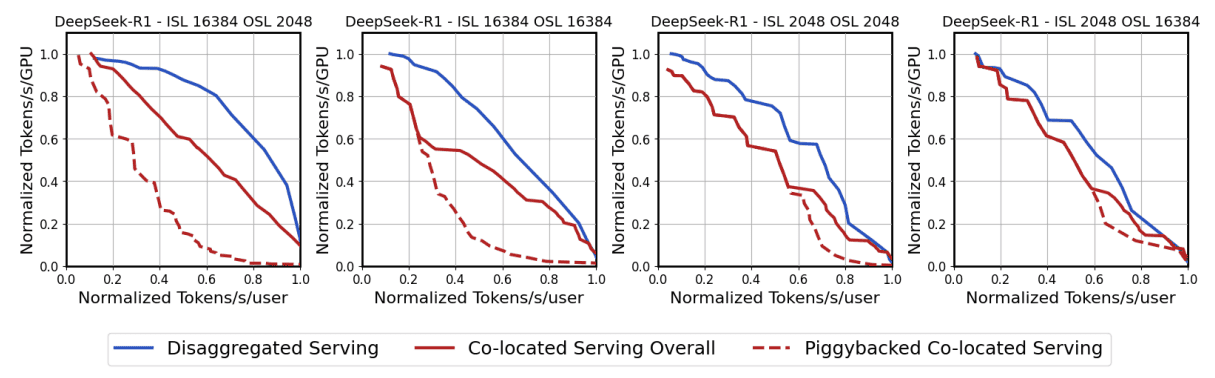
Figure 8: Disaggregation helps most under prefill-heavy traffic
- prefill-heavy traffic(ISL >> OSL)인 경우 dissaggregation에 의한 성능 향상 효과가 큽니다.
- 현실 세계에서의 트래픽 통계는 아래와 같았습니다.
- ISL: 평균 4500, 표준편차 3500
- OSL: 평균 750, 표준편차 750
Dynamic rate matching considerations
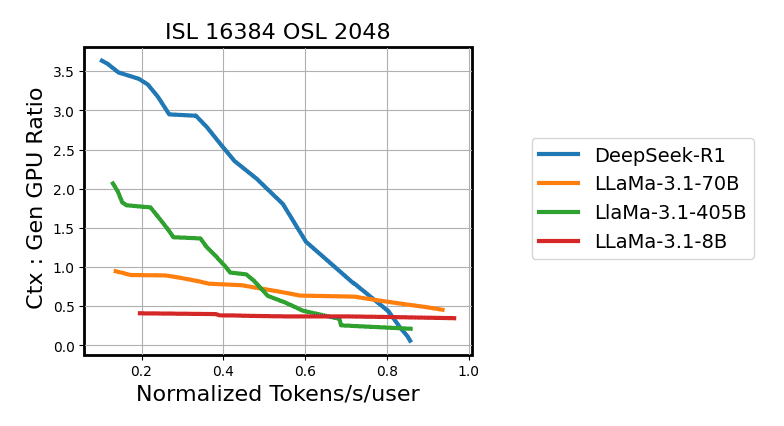
Figure 9: The optimal ratio of ctx-to-gen GPUs varies across models and target latencies.
prefill/decode가 작아질수록 tokens/s/user가 증가합니다.
NVLink sensitivity
NVLink로 더 많은 GPU를 연결할수록 EP, TP 크기의 선택폭이 넓어지면서 더 좋은 성능을 낼 수 있습니다.