Transformer (1706) - Attention Is All You Need
References
Transformer
왼쪽의 동일한 Layer를 반복적으로 쌓은 구조가 Encoder이고, 오른쪽의 동일한 Layer를 반복적으로 쌓은 구조가 Decoder입니다. Transformer는 Encoder와 Decoder로 구성되어 있습니다. Encoder는 입력된 문장을 이해하고, Decoder는 이해한 내용을 바탕으로 출력 문장을 생성합니다.
Tokenizer
Tokenizer는 문장을 입력하면 입력된 문장을 분리하여 토큰(Token)으로 변환합니다.
Input
오늘 날씨 어때?
Output
[128000, 58368, 105622, 105605, 107497, 101139, 106745, 30]
Embedding Layer
Embedding Layer는 입력된 토큰을 벡터로 변환합니다.
Input
[128000, 58368, 105622, 105605, 107497, 101139, 106745, 30]
Output
[[-1.4305e-04, 1.0777e-04, -1.9646e-04, ..., 2.0218e-04, 1.4842e-05, 3.0136e-04],
[-4.7607e-03, -8.0566e-03, -1.2390e-02, ..., -1.7624e-03, -2.7847e-04, -1.0132e-02],
[-8.7891e-03, 3.3264e-03, 1.1230e-02, ..., -5.2185e-03, -4.4250e-03, 1.1414e-02],
[-2.1667e-03, -5.1270e-03, -3.3417e-03, ..., 7.2937e-03, -8.5449e-03, 3.9978e-03],
[-1.4465e-02, -7.5073e-03, 1.2573e-02, ..., -2.1240e-02, 3.8452e-03, 7.4387e-04],
[ 7.9956e-03, -1.5991e-02, 4.8828e-03, ..., -1.6113e-02, 2.9907e-03, -8.2779e-04],
[-7.3547e-03, -1.9531e-02, -3.9978e-03, ..., -3.5095e-03, 1.9897e-02, 7.8735e-03],
[-4.9438e-03, -1.6098e-03, 6.4087e-03, ..., 1.9989e-03, -1.0147e-03, -4.8523e-03]]
Positional Encoding
Transformer는 RNN과 달리 입력된 순서에 의해 영향받는 것이 없기 때문에 입력된 순서를 알 수 있도록 Positional Encoding을 만들어 입력 토큰에 추가해야 합니다. 아래는 sin, cos을 활용하여 Positional Encoding을 만드는 예시 입니다.
Scaled Dot-Product Attention
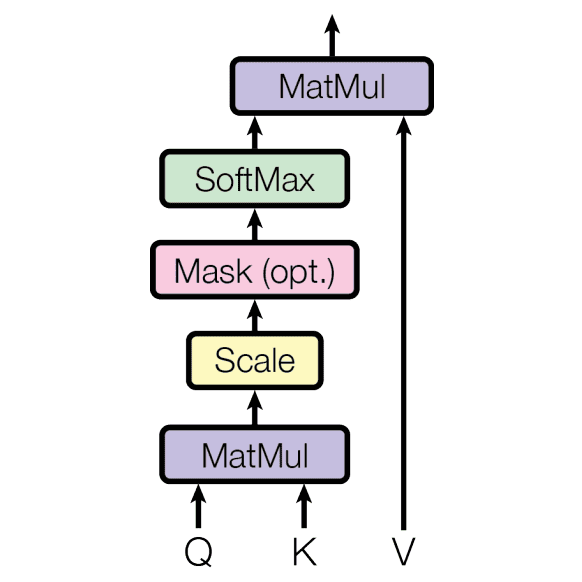
- Input
- Query
- Key
- Value
- Attention
- Output
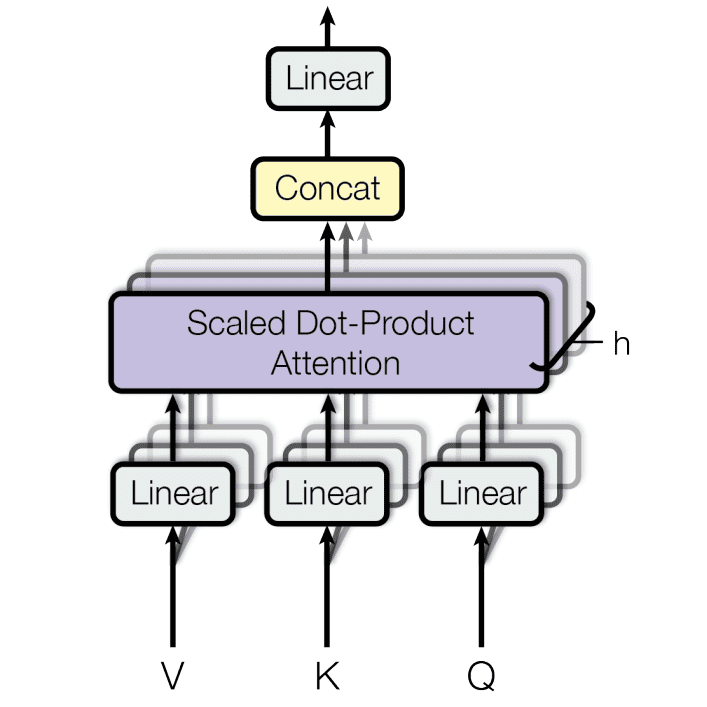
Multi-Head Attention (MHA)
Masked Multi-Head Attention
Cross Attention
Decoder에서 Cross Attention은 이전 레이어의 출력으로 Query를 만들고 Encoder의 출력으로 Key, Value를 만들어서 계산하는 Attention입니다.